Заметки о статьях по DeepLearning и ImageNet
Краткая заметка о содержании классических статей по сверточным нейронным сетям и ImageNet.
ImageNet classification with deep convolutional neural networks
Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. “Imagenet classification with deep convolutional neural networks.” Advances in neural information processing systems. 2012. [pdf] (AlexNet, Deep Learning Breakthrough)
Одна из классических статей, с которых начался современный виток диплернинга (сеть AlexNet).
Про ImageNet
Появление датасета ImageNet позволило решать задачу классификации изображений на качественно новом уровне. ImageNet содержит более 15 миллионов размеченных изображений, разбитых на 22000 категорий.
Начиная с 2010 года проводится соревнование ImageNet Large Scale Visual Recognition Challenge (ILSVRC) по распознаванию и детекции на ImageNet. Датасет соревнования представлен 1000 классов и разделен на 3 части: train 1.3M, validation 50k, test 100k. Качество классификации оценивается по 2 метрикам: ошибка на топ 1 и ошибка на топ 5.
Архитектура сети
Авторы использовали сверточную сеть из 8 слоев: 5 сверточных, 3 полносвязных. Последний слой — softmax на 1000 классов.
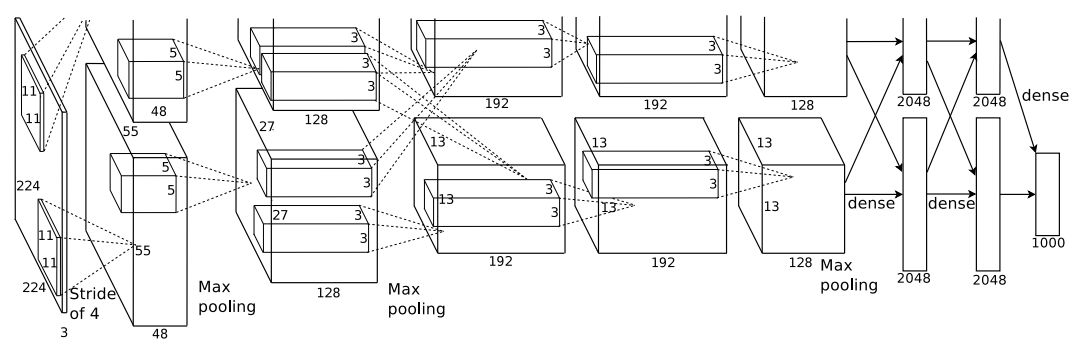 Оригинальная схема из статьи. (Да, она неправильно обрезана в статье.)
Оригинальная схема из статьи. (Да, она неправильно обрезана в статье.)
А еще в схеме есть забавная неточность.
Для тренировки сети все изображения масштабировали в 256x256. Препроцессинг — вычитание среднего (mean).
Функцией активации вместо общепринятых тогда сигмоида и tanh выбрали ReLU, что в несколько раз увеличило скорость обучения.
Хотя ReLU не требует нормализации данных, после экспериментов, авторы решили использовать локальную нормализацию (local normalization). Хитрая формула нормализации приведена в статье.
Борьба с оверфитом
Использовали 2 основных подхода: аугментации и дропаут.
Аугментации. Аугментированные изображения генерировали на лету с помощью Python и не хранили на диске. Пока сеть перемножала тензоры на GPU, через CPU обсчитывали новое аугментированное изображение.
Использовали 2 вида аугментаций:
- извлечение случайных фрагментов изображений 224x224 из изображения 256x256 и горизонтальное отображение этих фрагментов.
- изменение RGB компонет. Из imageNet с помощью PCA получили главные компоненты, которые хитрым способом сложили с оригинальными изображениями. Это уменьшило ошибку на тесте более чем на 1%.
Второй подход: дропаут с коэффициентом 0.5 в первых двух полносвязных слоях. На каждой итерации случайным образом половина нейронов не учавствовала в обучении, что улучшило обобщаущую способность сети.
Детали обучения
Модель обучали стохастическим градиентным спуском с импульсом (momentum) и затуханием (weight decay). Веса иницилизировали Гауссовым распределением с центром в 0 и среднеквадратическим отклонением 0.01.
Обучали на двух GPU GTX 580 (по 3Gb памяти) в течении 6 дней.
Полученные результаты:
- ошибка на топ 1: 35.7%
- ошибка на топ 5: 17.0%
Very deep convolutional networks for large-scale image recognition
Simonyan, Karen, and Andrew Zisserman. “Very deep convolutional networks for large-scale image recognition.” arXiv preprint arXiv:1409.1556 (2014). [pdf] (VGGNet,Neural Networks become very deep!)
Вторая классическая статья по сверточным сетям. Этой статье мы обязаны архитектурами VGG-16 и VGG-19.
Архитектура
Сеть организована по тем же принципам что в вышеприведенной статье. Для обучения использованы 224x224 RGB изображения, препроцессинг — вычитаение среднего (mean).
Ключевая особенность полученных сетей — использование маленьких сверток 3x3, что ползволило увеличить глубину до 16-19 слоев.
Ранее использовались свертки 5x5 и 7x7. Согласно статье использование двух сверточных слоев 3x3 заменяет один слой 5x5, а использование 3 слоев 3x3 заменяет один слой 7x7. Замена одной большой свертки на несколько маленьких позволяет увеличить число нелинейных преобразований и значительно уменьшить количество параметров сети.
После сверточных слоев идут два полносвязных слоя на 4096 нейронов и последний softmax слой на 1000. В качестве функции активации примененили ReLU.
От использования локальной нормализации из вышеприведенной статьи отказались, т.к. на тестах она не дала никаких преимуществ, зато увеличила потребление памяти.
Сеть обучали на оптимизацию множественной логистической регрессии, используя градиентный спуск с импульсом (momentum), регуляризацию L2 и дропаут на первых двух полносвязных слоях.
Веса инициализировали используя предварительное обучение на сети с меньшим количеством слоев и случайно инициализированными параметрами.
Реализация
Сеть собрали на Caffe, модифицировав для возможности обучения на нескольких GPU. Тренировка занимала 2-3 недели на 4х NVIDIA Titan Black.
Лучшие результаты на 1 сети:
- ошибка на топ 1: 24.4%
- ошибка на топ 5: 7.1%
Усреднение softmax классов нескольких сетей улучшило результаты:
- ошибка на топ 1: 23.7%
- ошибка на топ 5: 6.8%
Затем эту сеть применили к задаче локализации (определение баундинг-боксов объектов). Обучали аналогично задаче классификации, только логистическую регрессию заменили на Евклидово расстояние. Полученные результаты превзошли state of the art на момент написания статьи.
Сеть обученную на ImageNet применили к другим датасетам. Для этого выкинули последний полносвязный слой. Предпоследний слой, содержащий 4096 нейронов использовали в качестве извлекаемых из изображения признаков. К полученным признаками применили SVM классификатор с L2 регуляризацией. Веса предобученных слоев не меняли. На новых данных были получены результаты аналогичные либо превосходящие state of the art.
Going Deeper with Convolutions
Szegedy, Christian, et al. “Going deeper with convolutions.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015. [pdf] (GoogLeNet)
Статья про GoogleLeNet.
Архитектура
Архитектура сети получила название Inception (we need to go deeper).
Сверточные сети обычно имеют однотипную архитектуру: несколько сверток, pooling, полносвязные слои. Главное отличие Inception архитектуры в использовании новых Inception слоев.
Самый очевидный путь улучшения производительности нейронной сети — увеличение ее размера. Но больший размер сети, обычно, влечет увеличение числа параметров. Значит выше шанс оверфитнуться и ресурсов нужно больше. Эти проблемы можно решить используя разряженные слои вместо полносвязных. Но современное железо плохо справляется с разряженными структурами данных (кеш промахи).
Ключевая идея Inception — выяснить, как оптимальные локально-разряженные структуры сверточной сети могут быть аппроксимированы существующими неразряженными компонентами.
Inception слой одновременно применяет к предыдущему слою 1x1, 3x3 и 5x5 свертки, 3x3 пулинг и комбинирует результаты. Это проще один раз увидеть. Для уменьшения вычислительной сложности дополнительно используются 1x1 свертки.
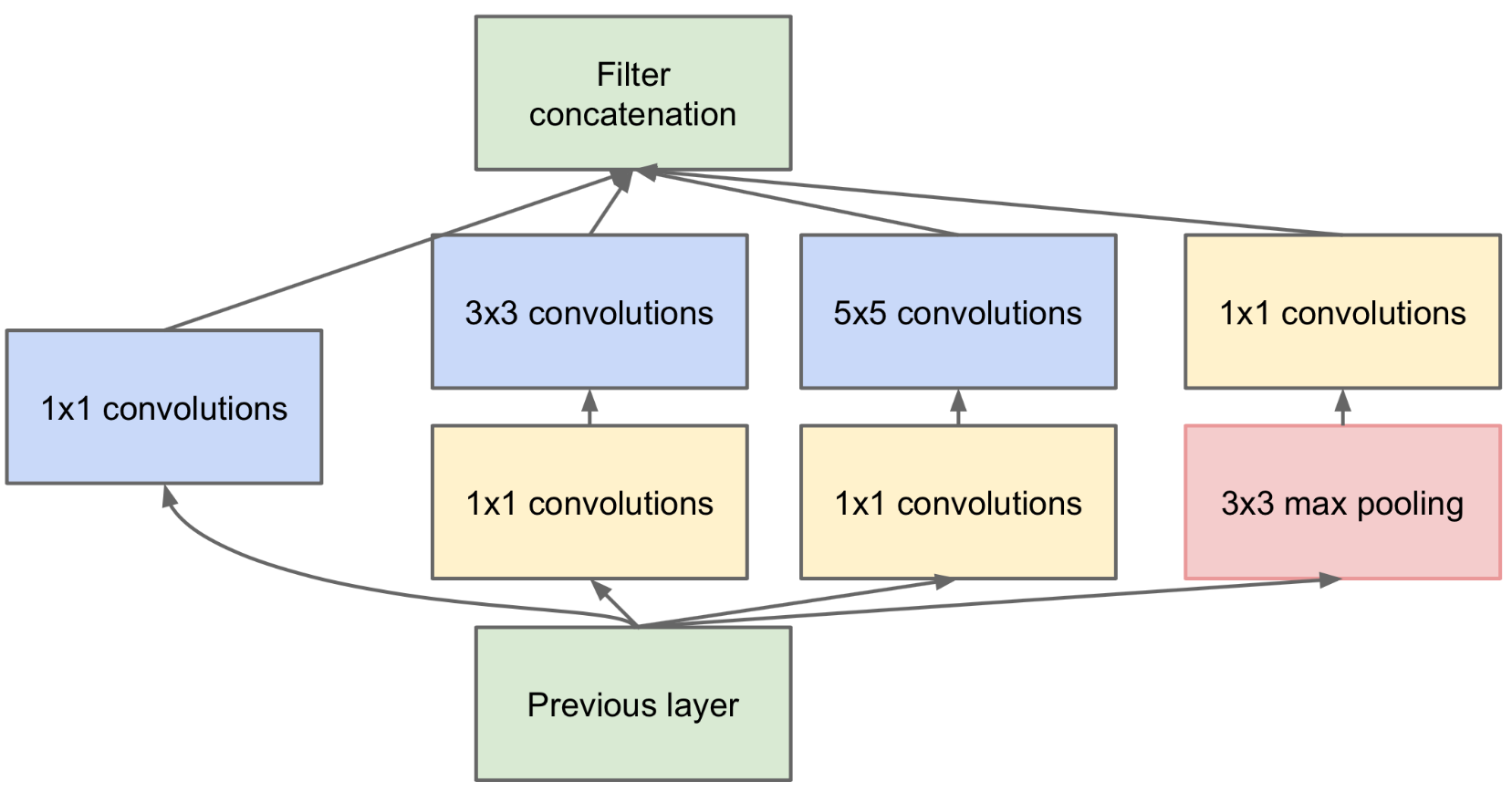 Схема Inception слоя.
Схема Inception слоя.
GoogleLeNet
GoogleLeNet является конкретной реализацией Inception архитектуры, использованной в соревновании ILSVRC 2014. Сеть содержит 22 слоя (27 если считать пулинг слои). На самом деле простых независимых слоев около 100.
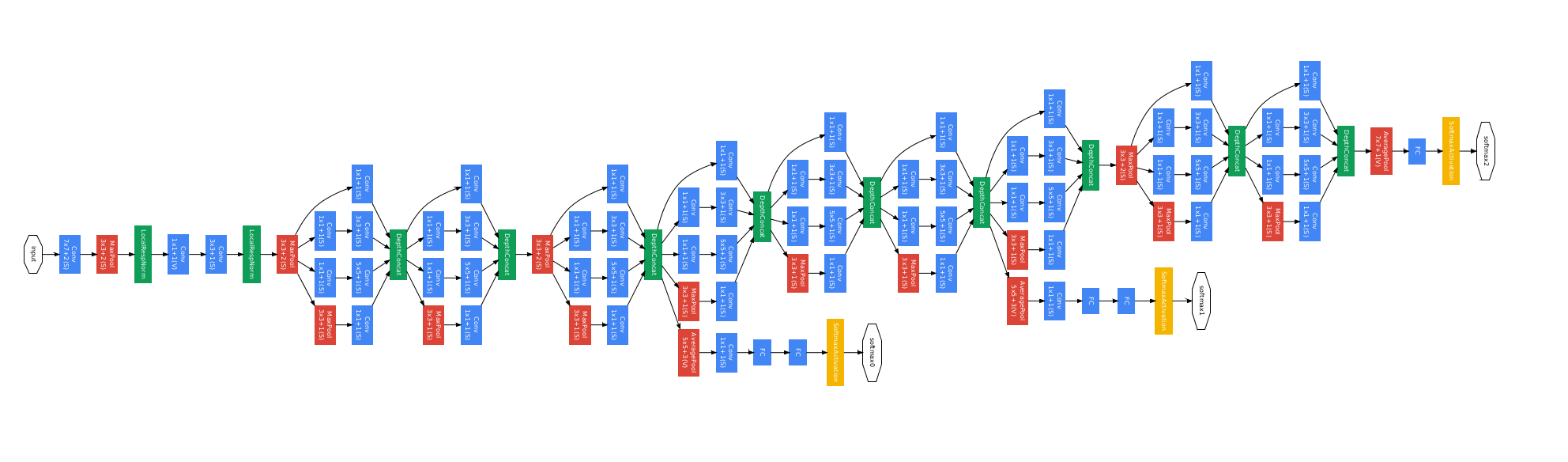 Схема GoogleLeNet.
Схема GoogleLeNet.
Функция активации: ReLU. Обучали стохастическим градиентным спуском с импульсом. Для улучшения backpropogation дополнительно использовали вспомогательные классификаторы на основе простых сверточных сетей.
Обучили 7 одинаковых сетей, с разным семплингом и рандомизацией входных изображений. Объединили в ансамбль, получили state of the art.
- Ошибка на топ 5: 6.67%.
Затем GoogleLeNet применили для детекции объектов, ансамбль из 6 сетей показал state of the art.