Деревья принятия решений в R
Дерево принятия решений - средство поддержки принятия решений, использующееся в статистике и анализе данных для прогнозных моделей.
Достоинством деревьев является возможность интерпретировать результат, то есть понять, какими решениями руководствуется модель при получении прогноза.
Рассмотрим пример простого дерева используя данные о пассажирах Титаника.
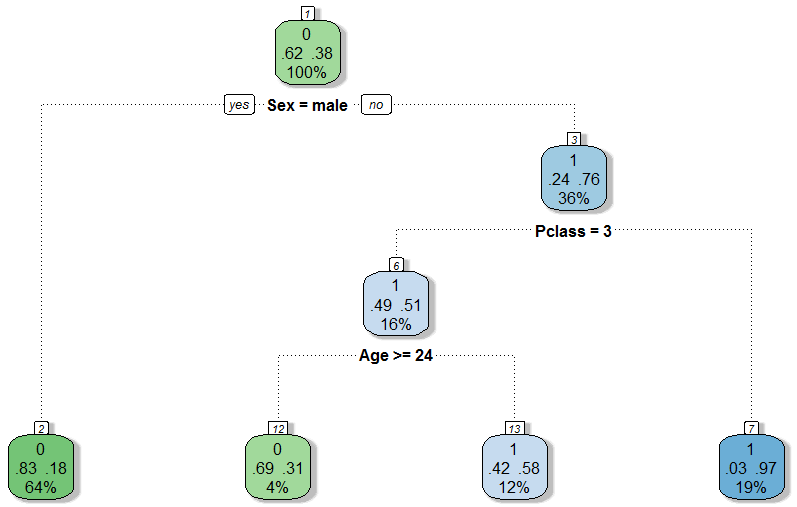
В корне дерева проверяется пол пассажира. Пассажиры мужского пола при этом определяются как погибшие (левое поддерево).
Для пассажиров-женщин проверяется следующее условие (правое поддерево), если пассажир путешествовал классом выше 3 модель определяет его как выжившего. Среди пассажиров третьего класса выжили пассажиры моложе 25 лет.
Это простое дерево решений верно предсказывает выживание пассажира в 75.7% случаев и позволяет сделать выводы о том, какие факторы повлияли на выживание пассажиров Титаника.
С точки зрения модели, больше шансов на выживание имели женщины, а при прочих равных выживали более молодые пассажиры, что кажется логичным. Зависимость выживания от класса, которым путешествовал пассажир, связана с тем, что каюты первого и второго классов на Титанике располагались на более высоких палубах, т.е. они раньше узнали о катастрофе и могли быстрее добраться до верхней палубы.
Модель дерева
Деревья принятия решений строятся на основе разбиения независимых переменных и имеют три ключевых параметра: minbucket, minsplit и cp.
minbucket - минимальное количество наблюдений, которое должно содержаться в каждом листе дерева.
При большом значении minbucket модель будет слишком общей, что отрицательно скажется на точности.
Если minbucket будет слишком низким возникает риск переобучения, модель будет показывать отличные результаты при обучении но окажется непригодной для работы с реальными данными.
minsplit - минимальное количество наблюдений, которые должны содержаться в вершине, чтобы попытаться разбить ее на несколько вершин.
cp (complexity parameter) - это метрика, которая останавливает ветвление дерева, когда оно уже не улучшает показатели модели.
# Подготовка данных
setwd("path/to/working/directory")
titanic <- read.csv("titanic.csv")
str(titanic)
titanic$Pclass <- as.factor(titanic$Pclass)
titanic$Survived <- as.factor(titanic$Survived)
titanic$Age[is.na(titanic$Age)] <- median(titanic$Age, na.rm=TRUE)
library(caTools)
set.seed(3000)
split <- sample.split(titanic$Survived, SplitRatio = 0.7)
Train <- subset(titanic, split == TRUE)
Test <- subset(titanic, split == FALSE)
# Установка и загрузка пакетов
install.packages("rpart")
install.packages("rpart.plot")
install.packages("rattle")
install.packages("RColorBrewer")
library(rpart)
library(rpart.plot)
library(rattle)
library(RColorBrewer)
# Строим модель
TitanicTree <- rpart(
Survived ~ Pclass + Sex + Age + SibSp + Parch + Fare,
data = Train, method = "class",
control=rpart.control(minbucket = 25)
)
# Изображение дерева
prp(TitanicTree) # Простое графическое изображение
fancyRpartPlot(TitanicTree) # Более наглядная версия, используемая в статье
# Получаем предсказания
PredictCART <- predict(TitanicTree, newdata = Test, type="class")
# Определяем точность
table(Test$Survived, PredictCART)
(156 + 54) / (156 + 54 + 49 + 9) # 0.7835821
# ROC кривая
library(ROCR)
PredictROC <- predict(TitanicTree, newdata = Test)
pref <- prediction(PredictROC[,2], Test$Survived)
perf <- performance(pref, "tpr", "fpr")
plot(perf)
Полученная модель:
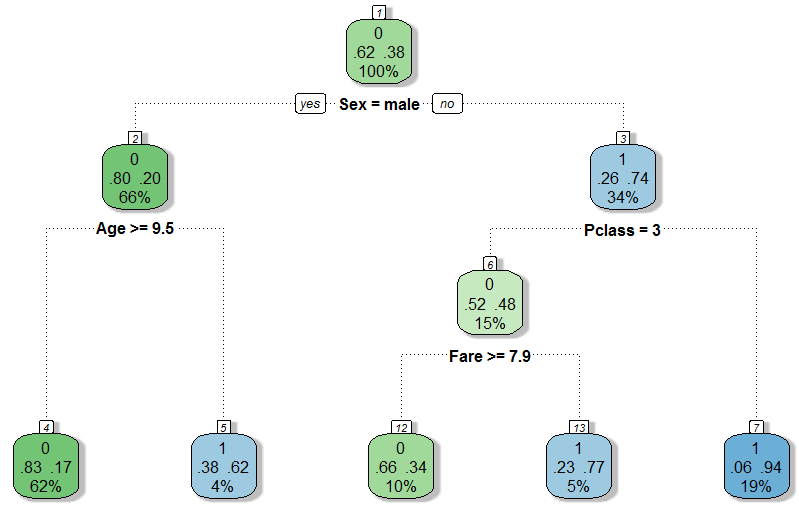
Точность модели $\approx78%$.
Кросс-валидация (K-folds Cross-Validation)
Метод кросс-валидации позволяет получить оптимальные параметры для построения дерева.
Разобьем тренировочные данные на $k$ частей (folds).
Для $i \in \overline{\rm 1..k}$:
Используем $k-1$ часть (все кроме $i$-й) для тренировки модели со всеми возможными значениями подбираемого параметра и протестируем получившиеся модели на оставшейся $i$-й части.
Имея тестовые данные определим значение параметра, дающее наилучшие результаты в среднем случае.
# Устанавливаем необходимые пакеты
install.packages("caret")
install.packages("e1071")
library(caret)
library(e1071)
# method="cv" - использовть кросс-валидацию
# number=30 - использовать 30 частей(folds)
fitControl <- trainControl(method="cv", number=30)
# Использовть значения cp от 0.001 до 0.2
cartGrid <- expand.grid(.cp=(1:200)*0.001)
# !ВАЖНО: Зависимая переменная должна иметь тип factor
# Кросс-валидация
train(
Survived ~ Pclass + Sex + Age + SibSp + Parch + Fare,
data=Train,
method="rpart",
trControl=fitControl,
tuneGrid=cartGrid
)
# Результатом будет таблица, содержащая различные значения точности(Accuracy) для различных cp
# Нам нужен cp, который дает максимальную точность, он указан в конце вывода функции
cp Accuracy Kappa Accuracy SD Kappa SD
0.001 0.7882540 0.5467110 0.08778277 0.1844922
0.002 0.7882540 0.5467110 0.08778277 0.1844922
...
0.199 0.8006349 0.5712707 0.08858082 0.1907386
0.200 0.8006349 0.5712707 0.08858082 0.1907386
Accuracy was used to select the optimal model using the largest value.
The final value used for the model was cp = 0.006 # Нужное значение
# Полученный cp необходимо использовать в функции rpart в качестве параметра
# control=rpart.control(cp=)
TitanicTree <- rpart(
Survived ~ Pclass + Sex + Age + SibSp + Parch + Fare,
data=Train,
method="class",
control=rpart.control(cp = 0.006)
)
# Рассмотрим получившееся дерево
fancyRpartPlot(TitanicTree)
PredictCART <- predict(TitanicTree, newdata = Test, type="class")
table(Test$Survived, PredictCART)
(152 + 61) / (152 + 61 + 42 + 13) # 0.7947761
Дерево полученное в результате использования параметра cp после кросс-валидации:
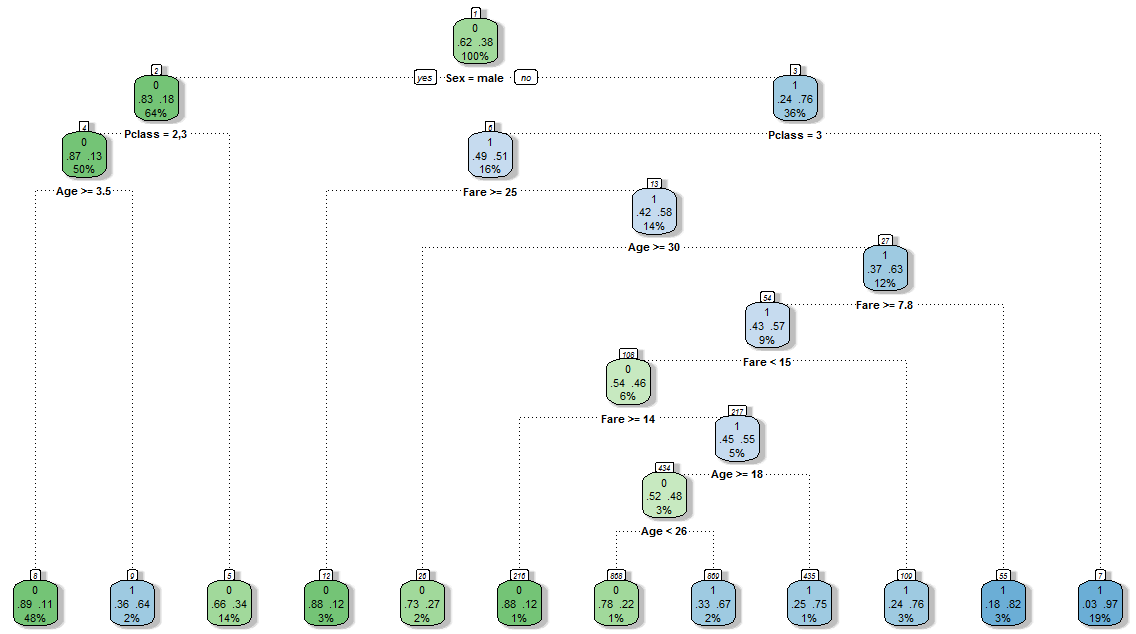
Точность новой модели $\approx79.5%$.
Случайный лес (Random forest)
Этот алгоритм был разработан для улучшения предсказывающих качеств деревьев и основан на построении большого количества разных деревьев. Ценой улучшения предсказывающих способностей является ухудшение интерпретируемости результатов.
Чтобы сделать предсказание с помощью случайного леса каждое дерево голосует за определенный результат, предсказанием модели является прогноз с наибольшим количеством голосов.
Основные параметры случайного леса:
- Минимальное количество наблюдений в подмножестве (
nodesize) - Количество деревьев (
ntree)
# Устанавливаем необходимый пакет
install.packages("randomForest")
library(randomForest)
# !ВАЖНО: Зависимая переменная должна иметь тип factor
# Построение случайного леса
TrainForest <- randomForest(
Survived ~ Pclass + Sex + Age + SibSp + Parch + Fare,
data=Train,
nodesize=25,
ntree=200
)
# Получаем предсказания
PredictForest <- predict(TrainForest, newdata = Test)
# Точность модели
table(Test$Survived, PredictForest)
(151 + 65) / (151 + 65 + 38 + 14) # 0.8059701
Полученный лес имеет точность $\approx80.6%$ на тестовом наборе данных и превосходит дерево принятия решений.
Кросс-валадацию для случайного леса можно не использовать, так как лес устойчив к незначительным атрибутам и менее подвержен переобучению.